Tools
The source code of many of our tools can be found on our Descartes Research GitHub repository.
Actively Maintained Tools
COFFEE
COFFEE (short for Container Orchestration Frameworks' Full Experimental Evaluation) is a benchmarking framework for container orchestration frameworks. It is able to automate repeatable experiments and covers many aspects for modern container orchestration frameworks.
Libra
Libra, a forecasting benchmark, automatically evaluates and ranks forecasting methods based on their performance in a diverse set of evaluation scenarios. The benchmark comprises four different use cases, each covering 100 heterogeneous time series taken from different domains.

TeaStore
The TeaStore is a distributed micro-service application featuring five distinct services plus a registry. It is designed to be a reference / test application to be used in benchmarks and tests. Some of its envisioned use-cases are:
- Testing performance model extractors and predictors for distributed applications
- Testing micro-service and cloud management mechanisms, such as multi-tier auto-scalers
- Testing energy efficiency and power prediction and management mechanisms
Each of the TeaStore's services may be replicated without limit and deployed on separate devices as desired. Services communicate using REST and are also available in a pre-instrumented variant that uses Kieker to provide detailed information about the TeaStore's actions and behavior.

Telescope
Telescope is a hybrid forecasting tool written in R and designed to perform multi-step-ahead forecasts for univariate time series while maintaining a short runtime. The forecasting method is based on STL time series decomposition. To achieve better forecasting results, Telescope uses clustering techniques for categorical information creation and ARIMA, ANN, and XGBoost as forecasting methods. Telescope users can pass a matrix of timestamps and observation values, set the length of the forecasting horizon, and also set various optional parameters.
Previous Tools
BUNGEE Cloud Elasticity Benchmark
BUNGEE is a Java based framework for benchmarking elasticity of IaaS cloud platforms. The tool automates the following benchmarking activities:
- A system analysis evaluates the load processing capabilities of the benchmarked platform at different scaling stages.
- The benchmark calibration uses the system analysis results and adjusts a given load intensity profile in a system specific manner.
- The measurement activity exposes the platform to a varying load according to the adjusted intensity profile.
- The elasticity evaluation measures the quality of the observed elastic behavior using a set of elasticity metrics.

Chameleon
Chameleon is a hybrid auto-scaling mechanism combining multiple different proactive methods coupled with a reactive fallback. Chameleon reconfigures the deployment of an application in a way that the supply of resources matches the current and estimated future demand for resources as closely as possible according to the definition of elasticity.
Descartes Modeling Language
The Descartes Modeling Language (DML) isan architecture-level modeling language for quality-of-service and resource management of modern dynamic IT systems and infrastructures. DML is designed to serve as a basis for self-aware systems management during operation, ensuring that system quality-of-service requirements are continuously satisfied while infrastructure resources are utilized as efficiently as possible. The term quality-of-service (QoS) is used to refer to performance (response time, throughput, scalability and efficiency) and dependability (availability, reliability and security). The current version of DML is focused on performance and availability, however, the modeling language itself is designed in a generic fashion and it is intended to eventually support further QoS properties.
DNI - Descartes Network Infrastructures Modeling
DNI is a family of meta-models designed for modeling the performance of communication networks. DNI is tightly related to DML and the main modelingdomain are data center networks. A user can model network topology, switches, routers, servers, virtual machines, deployment of software, network protocols, routes, flow-based configuration and other relevant network parts. DNI can be used to model any type of network as it was designed to be as generic as possible.
Descartes Query Language
Available approaches for performance prediction are usually based on their own modeling formalism and analysis tools. Users are forced to gain detailed knowledge about these approaches before predictions can be made. To lower these efforts, intermediate modeling approaches simplify the preparation and triggering of performance predictions. However, users still have to work with different tools suffering from integration, providing non-unified interfaces and the lack of interfaces to trigger performance predictions automatically.
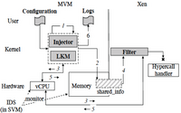
hInjector
hInjector is a tool for injecting hypercall attacks in virtualized environments for the purpose of evaluating hypercall security mechanisms - intrusion detection systems and mandatory access control mechanisms. hInjector injects hypercall attacks during regular operation of guest virtual machines, crafted with respect to representative attack models. The current implementation of hInjector is for the Xen hypervisor, which can be ported to other open-source hypervisors, such as KVM.

HTTP Load Generator
The HTTP Load Generator is a load generator designed to generate HTTP loads with varying load intensities. It uses load intensity specifications as specified by LIMBO to generate loads that vary in intensity (number of requests per second) over time. The load generator logs application level data and supports connecting to external power measurement daemons. It specifies the http requests themselves using LUA scripts, which are read at run-time.

Library for Resource Demand Estimation
When creating a performance model, it is necessary to quantify the amount of resources consumed by an application serving individual requests. In distributed enterprise systems, these resource demands usually cannot be observed directly, their estimation is a major challenge. Different statistical approaches to resource demand estimation based on monitoring data have been proposed, e.g., using linear regression or Kalman filtering techniques.

LIMBO Load Intensity Modeling Tool
LIMBO is an Eclipse-based tool for handling and instantiating load intensity models based on the Descartes Load Intensity Model (DLIM). LIMBO users can define variable arrival rates for a multitude of purposes, such as custom request time-stamp generation for benchmarking or the re-parametrization of request traces. LIMBO offers an accessible way of editing DLIM instances and extracting them from existingtraces. It also supports additional modeling utilities, such as using high level - DLIM (hl-DLIM) parameters for easy creation of new DLIM instances through a model creation wizard.
![]()
Performance Model eXtractor
The manual creation of architectural performance models is very complex, time intense and error prone. The Performance Model eXtractor (PMX) tool automates the extraction of architectural performance models form measurement data. Currently, PMX supports logs of the Kieker Monitoring Framework as input data format and returns a Palladio Component Model. For the future we plan to add the extraction of Descartes Modeling Language to PMX.

Prisma
PRISMA is a framework for online model extraction in virtualized environments. The framework consists of a server component and different agents.
![]()
QPME
QPME (Queueing Petri net Modeling Environment) is an open-source tool for stochastic modeling and analysis based on the Queueing Petri Net (QPN) modeling formalism. The development of the tool started in 2003 at the Technische Universität Darmstadt and was continued at the University of Cambridge from 2006 to 2008 and at the Karlsruhe Institute of Technology (KIT) from 2008 to 2014. Since 2014, QPME is developed and maintained by the Chair of Software Engineering at the University of Würzburg. The first version was released in January 2007 and since then the tool has been distributed to more than 120 organizations worldwide (universities, companies and research institutes). Since May 2011, QPME is distributed under the Eclipse Public License.
Regression Library
The Regression Library is a collection of R scripts, designed for automated regression, optimization and evaluation of different standard regression approaches. The library was originally created as part of the SPA tool for analyzing storage performance, but is applicable for any kind of regression problem.
Storage Performance Analyzer (SPA)
The Storage Performance Analyzer (SPA) is a software package containing the functionality for the systematic measurement, analysis and regression modeling specifically tailored for storage systems. SPA consists of a benchmark harness that coordinates and controls the execution of the included I/O benchmarks (FFSB and Filebench) and a tailored analysis library used to process and evaluate the collected measurements.
Univariate Interpolation Library
The Univariate Interpolation Library is a Java 8 library for interpolating data sets of 2D-vectors using univariate functions. The library implements a great range of different interpolation methods and contains functionality to automatically select a good one for any given data set. The automated selection can either be achieved using an independent reference dataset or no additional data at all.
WCF Workload Classification & Forecasting Tool
The Workload Classification & Forecasting (WCF) tool provides continuous forecast results that are supposed to be interpreted by resource management components to enable proactive resource provisioning. A WCF user can flexibly define his objectives to the forecast results and their processing like time horizon, confidence level and processing overhead limitations. He is not supposed to select a certain forecasting method. A key feature of the WCF tool is that it is internally using a spectrum of forecasting methods based on time series analysis like ARIMA, Extended Exponential Smoothing (ETS), tBATS, etc. The method with the most accurate results for a given situation is selected dynamically during runtime by using a decision tree und feedback mechanisms.
Mailing List
To stay updated on our tools, please subscribe to our descartes-tools mailing list (low traffic, only announcements related to our tools)